2K

Swift 的String 是 Unicode String 因此使用Sort(by:) 時自然是使用Unicode 排序
這樣的好處是無論是什麼樣的文字,找得到Unicode 編碼就可以排序
什麼是Unicode?
Unicode是一種文字編碼方式,常見的有UTF-8 與 UTF-16,最顯而易見的差別在於位元數的不同
由於Unicode幾乎包含所有文字,因此在Swift 裡基本上所以文字都可以使用 Sort(by:)來排序
但是問題來了,使用Unicode排序是很方便沒錯,但是卻可能與認知的文字排序不同
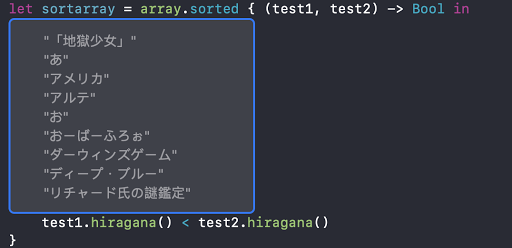
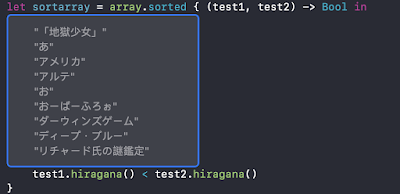
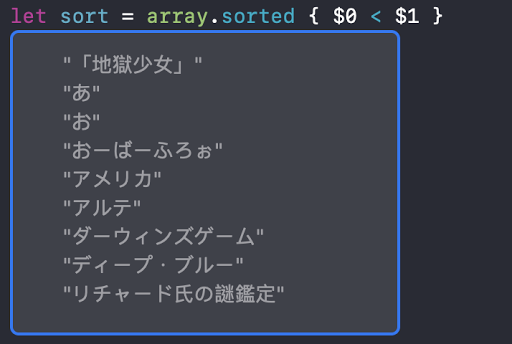
就拿專案上遇到的日文字來舉例
由於日文有平假名與片假名,若直接使用Unicode來排序的話,發生 あ < ア 的情況,這是因為Unicode 的編碼中 あ 是排在 ア 的前面,排序的時候自然就會出現 あ < ア的情況,看起來很合理沒什麼問題
但問題在於對於日本人來說 あ = ア 所以它們在順序上是同等的,那該怎麼辨呢?
這時候就請出Google 大神!!! 在 Google 大神的幫忙下有找到了日本開發者寫的方法
Stringクラスにひらがな・カタカナ変換をextensionする
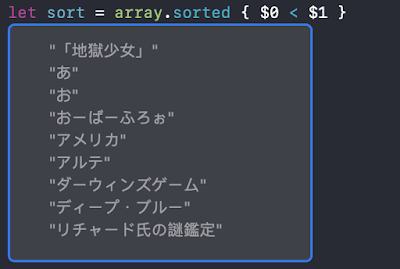
這個解法簡單來說就是先把平假名轉成片假名,或是把片假名轉成平假名之後,再使用Sort 來排序
這樣排出來的就會是完美的五十音順啦~ 趕快來試用看看吧…
呃…
ERROR…

研究了一下子,終於發現了問題點,只要改寫成下面這樣就可以了
if char.value >= 0x30A1 && char.value <= 0x30F6 {
if let code = UnicodeScalar(char.value - 96) {
hiragan.append(Character(code))
} else {
hiragan.append(Character(code))
}
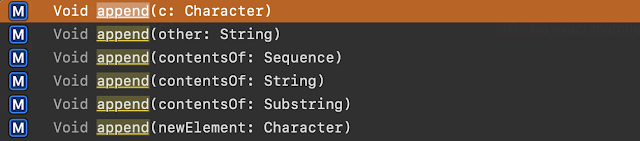
}主要原因
是現在的(Swift 5) append只有提供這些方式
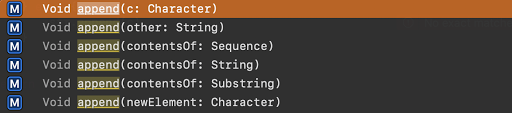
因此Github中原本使用的方式就不能用了,已經不能直接把UnicodeScalar加到String裡,必需要轉成Character之後才能丟進去
把轉換method改寫完之後,就可以排出 あ = ア 的五十音排序了